



Reachability has quickly become one of the latest buzzwords in cybersecurity, but every vendor means something slightly different by the term. In part one of this series, I argued that reachability is really about only showing exploitable vulnerabilities. In part two, I compared runtime and static reachability to determine that if the goal of reachability analysis is to only fix exploitable vulnerabilities, only runtime reachability will get us there.
The final question to address is, “Which type of runtime reachability is the right kind?” In 2025, almost every vendor uses the term reachability, alongside a nifty funnel showing your vulnerability count going down, but vendors almost always mean different things by the term. In this article, we’ll explore the complexity of reachability types, and how while there’s no silver bullet, function level reachability for vulnerabilities is the best overall answer to the problem.
Flavors of Runtime Reachability
All excalidraws are available here

Security engineers are desperate for ways to make the thousands of false positive vulnerabilities disappear from their vulnerability reports. From new Linux distros (distroless 🙄) to network attack paths to blast radius, there are more proposals than ever for “prioritization” and “reducing the noise.” As I’ve argued over the course of this series on reachability – the real goal is to get as close as possible to “exploitability.” Businesses only want to commit resources to fix things that are exploitable.
The scenario is common: a new 9.5 severity CVE is released, and the Cybersecurity Socials are abuzz with complaints that “it’s not really that bad.” The unfortunate nature of vulnerability disclosure necessitates that CVE base scores are assigned based on worst case scenarios rather than the context of your unique environment – you’re meant to do environmental re-scoring. Because core open source packages exist across an incredible number of contexts, most findings are totally unrelated to your environment. Additionally, security researchers are usually making things work in unusual ways in order to show an exploit.
An example of critical CVE’s that aren’t critical for most users are three critical vulnerabilities from Log4j 1.x (note: not for log4shell which was 2.x, but the older version). These three vulnerabilities are all related to critical remote code execution vulnerabilities in the Log4J package; however, they can only be exploited in the context of Apache Chainsaw, which is a GUI for Log4J to allow developers to explore logs. While Log4J is widely distributed, the GUI via Apache Chainsaw is much less widely utilized – especially in modern environments. It’s also not usually publicly facing. But to a traditional vulnerability scanner without context, these are all alarm bell vulnerabilities.
Here are the problems this set of vulnerabilities reveals about the larger vulnerability ecosystem:
- Many of the most critical vulnerabilities are not applicable in most contexts
- Security teams, and even developers, can’t be complete masters of every library they use or import
- The vulnerability system often does not provide enough data to make accurate determinations of real risk for most people.
- Many tools fail to adequately distinguish between OS vulnerabilities, like an openSSH package, and code library vulnerabilities, such as Log4J
These vulnerabilities illustrate the numerous problems faced by security teams, but the core problem is this: it takes way more time and people to investigate a vulnerability than to discover that it exists. A security engineer’s gut reaction to a vulnerability is to try and recreate a PoC to convince developers to fix it, but this is unrealistic for thousands of vulnerabilities.
Runtime reachability offers a solution to this investigation problem: only show me vulnerabilities that are actually exploitable in my environment. Only by looking at the application while it’s running can tools effectively distinguish what’s exploitable or not. While I’ve talked elsewhere about some of the benefits of a “shift left” or static approach to reachability, in that it can run before production, the critical limitation of that technique is that it is always at best theoretical. For example, the best shift left reachability in the world cannot tell me whether or not I’m actually using Apache Chainsaw – only something watching the runtime can tell me if developers are utilizing the GUI.

In our last article we compared static and runtime reachability, determining that static reachability has the benefit of running pre-production, but only runtime reachability can tell you what’s actually exploitable – getting closer to the ideal of no false positives. I can say from my time using the tools that the results of true runtime reachability are impossible to ignore once you see them; unfortunately, the market is crowded with oversimplifications and false statements such as:
❌ All eBPF agents are the same
❌ A package loading is reachability
❌ A package executing is reachability
❌ Showing if a service is network facing is reachability
What makes this even more confusing is that different vulnerabilities actually benefit more or less from different types of reachability! Here’s a graph illustrating the complexity of the issue, and the different ways a vulnerability may or may not be exploitable in your environment:
 |
| Different vulnerabilities that may exist and be exploitable based on where they live in a workload |
This graph shows vulnerabilities that may exist in different layers of your workload, but are only exploitable when they’re in that specific layer. Each of these exploited vulnerabilities occur in different layers of the cloud and application environments – from third parties, to OS exploits, to application exploits and even cloud, its clear reachability isn’t so simple.
In the rest of the article, we’ll explore the state of different runtime reachability solutions, as well as their pros and cons.
The complexity of Runtime Reachability
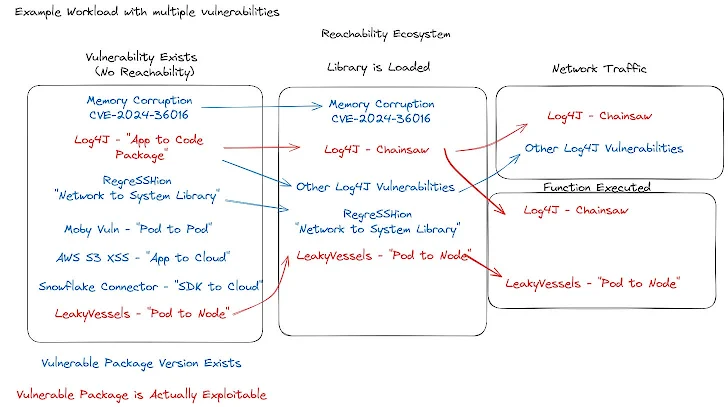 |
| Vulnerability reduction based on reachability type – red is actually exploitable, blue is a false positive |
This image is a lot, let’s take a minute and break it down. Let’s pretend we have a container image that’s used for viewing Java logs, that also builds container images – because you have some Java nerds, you’re using Chainsaw to view build logs where anything goes wrong, and this is exposed to the network traffic behind a VPN. Here, I took 7 “in the news” vulnerabilities that might all get detected on the same workload. However, in this example, only two of the vulnerabilities are actually exploitable (red): Log4J (Chainsaw) and LeakyVessels. The blue are non-exploitable vulnerabilities that are on the image. We can use the flow to see how different types of reachability would rightly or wrongly prioritize or de-prioritize these issues.
First, by detecting if a library is loaded, we correctly filter out some amount of false positives. This is a great baseline methodology for just doing some basic filtering – if something isn’t loaded into memory, then it’s definitely not running in a way that could be actively exploited. It is worth noting that even if something isn’t loaded, if an attack ever does get on the system, libraries can become loaded very quickly!
As a brief aside, some tools now use the term “executed” to distinguish from “loaded,” but in practice, this distinction often doesn’t add much value. “Loaded” usually refers to a shared library being mapped into a process’s memory space. “Executed” typically means that some code within the loaded file has actually been run.
However, we need to highlight the massive difference between higher level “execution” and “function level execution.” Function level execution doesn’t just look at what files are accessed, but at which specific functions from the code are executing. This provides tremendous prioritization value – the average library contains hundreds or thousands of functions, and most exploits are about exploiting a specific one, in a specific context. In my testing, function level execution means 10-100x more value in terms of deprioritizing false positives.
Network reachability is interesting because it rightly prioritizes some things, but also prioritizes some red herrings – for example, most vulnerabilities require other configuration errors besides being internet facing to exploit. Additionally, it can falsely de-prioritize findings – such as missing service to service calls, or missing vulnerabilities that don’t need network access to exploit. Overall, network reachability is inconsistent in its usefulness. There’s an intuitive layer to it – if the internet can’t reach a service surely it can’t be exploited? But that intuitiveness doesn’t always match the complicated reality.
Devices, supply chains, and services are all connected in different ways, regardless of their internet connectivity. Many exploits rely on supply chains, or downstream services, and these vulnerabilities are all falsely hidden if over-relying on network reachability. Furthermore, there’s a lot of nuance to what being “internet reachability” really means, with most vendors making it a binary option rather than something more clear like the number of hops a service is from the internet.
Everything’s Reachable, What Kind do I Need!?

While it would be fun to say that there’s a silver bullet of reachability, the truth is that you really need all of them depending on the vulnerability. Take one of the most recent big vulnerabilities – the next-js middleware auth bypass. The TL;DR is that the vulnerability left you completely compromised if you used next.js middleware for authentication. Key to determining if you’re vulnerable is “When a next.js application uses a middleware, the runMiddleware function is used… (it) retrieves the value of the x-middleware-subrequest header and uses it to know if the middleware should be applied or not.”
Thinking through our loaded, function executed, network reachability paradigm:
- Loaded or Basic Execution: Nextjs loads as an entire library, so this would just tell you wherever you’re using nextjs, but not middleware specifically – so it doesn’t help prioritize much, but at least it’s not wrong
- Network Reachable: This would help us prioritize a fix, because certainly a public facing nextjs app would be more critical than an internal one; however, once again it doesn’t help prioritize much beyond if we have intranet nextjs.
- Function Execution: This is the true prioritization method – it would tell us not only which workloads are loading nextjs, but which ones actually use the middleware functions.
While not every vulnerability follows these trends, it’s clear that in utility: function level > loaded > network reachability. So, why doesn’t every vendor do function level execution?

Loaded is used because it’s easy to do. It’s always a good method for de-prioritization because it will never be wrong – if something’s not loaded it can’t be an initial exploit. However it falsely prioritizes things since plenty of things are loaded without executing the vulnerable functions.
Network is used because it’s intuitive to security. It’s sometimes helpful for prioritization, but is dangerous because it falsely de-prioritizes vulnerabilities that may be executing even if they’re not directly receiving internet traffic – especially supply chain attacks. Furthermore, network reachability is often inaccurate in containerized microservice environments where service to service traffic oftentimes isn’t accounted for.
Function level visibility is the only way to get both trustworthy de-prioritization and prioritization of a vulnerability. If a vulnerable function isn’t executing, the CVE can’t be an initial exploit. Similarly, if it is executing, you know there is potential to exploit that absolutely should be investigated. Its only two weaknesses are: first, not every CVE is related to a specific function, in which case the feature doesn’t help. Second, it’s theoretically possible to have zombie endpoints that an attacker discovers. But in the latter case, the attacker would need to execute the function to trigger the vulnerability, at which point it would be blocked or prioritized.
Another Thing: OS vs. Code Libraries
I’ve talked about this in the past, but everything we’ve talked about applies to both code libraries (installed via a package manager, like next.js and package.json) and OS libraries (installed via the distro package manager, like OpenSSH and APT). Not all scanning tools detect all of these, so it’s an important note that everything we’ve talked about applies, but code library support doesn’t exist with all OS scanners, and vice versa.
It’s worth asking your vendor what they support, but here’s a general guide:
| Reachability Type | System Library Support | Code Library Support |
|---|---|---|
| None | CNAPPs | Mixed support since Trivy supports some libraries, so usually traditional SCA tools are needed alongside |
| Package Loaded | Some CNAPPs, requires an agent | Mixed support depending on language |
| Network Reachability | Newer CNAPPs, but very few tell you how many hops a service is from the internet | Mixed support depending on language |
| Function Executed | Only Raven, Miggo, Oligo, and Kodem | These vendors also support code libraries |
Conclusion

There’s something magical about each one of these 17 vulnerabilities being interesting and relevant. It makes every investigation a valuable use of time, rather than drowning in a sea of false positives that aren’t even relevant to your application in the slightest.
That was all a lot to take in, so here’s the TL;DR:
- Not all runtime reachability is the same
- There are really three types: Loaded, Network, and Function execution
- Depending on the type of vulnerability, there are pros and cons to each approach, but function level provides by far the most true positive value
Ultimately, it’s hard to overstate the feeling of seeing only your vulnerable executing functions at runtime. These results are always interesting, which is far more than I can say about most other types of scanning out there. If you’re tired of wasting your time hunting down meaningless vulnerabilities, I can’t recommend function level vulnerability enough.
About the Author: James Berthoty, CEO & Principal Analyst at Latio, founded the engineering-first analyst firm after 10 years in cloud and application security to help practitioners make informed security product decisions—guided by Latio’s mission to be accurate, timely, and unapologetically opinionated.
James Berthoty — CEO and Principal Analyst at Latio
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi6SPfBfENVva3CEOSqQTnB9S2jdmrPgTSGWPStWdg7-sRrcYke8zKSTeA6kasFVshQtmgSsuHV38p7ddcS_Adxd0yreSF7rPoAqOrJP1iMjwkAs3WFkGXlIn4nnUizxwsafPYxYvxaayoxcw1z9177m5ofrGgd42WehZ_Gm4xl_r8EZD1JdYT9DsT2xNU/s728-rw-e365/james.png
